In the previous section a brief description of the various TCP/IP protocols was given. They are the base from which we developed our design. We tried to combine the benefits of an object oriented language with speed. The benefits gained from object orientation is reusable code, and code that is easy to maintain.
We based our stack on two basic principles. The first one was to keep it as simple as possible. The second was to make it fast. Sometimes we had to chose between either speed or simplicity; we made our best to combine them in those cases.
We used several solutions to gain speed in our implementation; some of them are benefits from the programming language, others are benefits of an efficient design. Often when designing a stack each protocol is represented by separate processes. And the communication between the protocols is done by sending messages between the processes. Instead we tried to have the handling of each packet run as a separate process, and thus reducing the need for context switches.
The most important part of the design was the packet class. The packets are used when sending and receiving data, and thus they are very important to the performance of the stack. If the handling of a packet is slow, the whole stack will be affected; therefore we put extra effort into making the packets efficient. We designed the packets to be able to handle data located at different locations. This was a way to avoid unnecessary copying of the data.
It was decided that we should implement the protocol stack in the C++ language [9]. C++ is an object oriented language based on the C programming language (C is the language which most protocol stacks of today are written in). C++ offers the class as a way to keep code and data pertaining to one task contained together. A class can inherit functions from other classes providing a way to share a common interface, but with differing implementations. This allows for an easy exchange of e.g. the class handling hardware dependencies. With a good design C++ programs can be shorter and easier to maintain than their C counterparts. There are also common class libraries, providing classes for the most common problems. One of these is STL which provides classes that handle often used algorithms and data structures, such as linked lists, maps, sets and so on [10].
Programs written in C++ have a reputation of being slower than similar programs written in C. This imposed a few special requirements on our design to not affect its performance. In C++, dynamically allocating objects on the heap may take a considerable amount of time if not handled wisely. A way around this problem is to allocate often used objects in advance, and reuse them instead of destroying them. In general, oftenly used code should be designed to be as fast as possible, while routines only executed once do not have the same constraints. Also routines that work on every byte in the packet should be optimized for speed. Examples of where speed is a vital design factor is in the routines calculating the checksums for the various protocols, and the routines doing the encoding and decoding of the packet.
During the design it is decided what classes to use. The class hierarchy and the connections between the classes are described. Decisions about which attributes and member functions needed in the classes are also made. We have used the OMT model for our design [11].
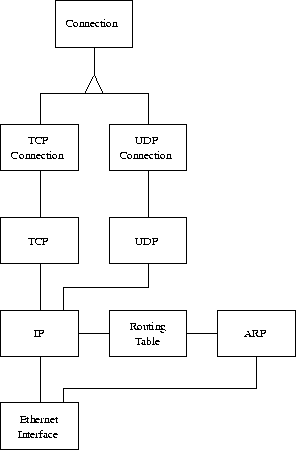
The structure of the classes is quite simple; one class for each protocol. There are two types of connections: TCP connections and UDP connections, depending on which protocol is to be used when sending data. They derive from a common connection class, making them look the same to an application. Below the connection level is either TCP or UDP. They implement the functions in the TCP or UDP protocol. Below this level is the IP class. Among the more important algorithms implemented by IP are fragmentation and reassembly. IP uses a class RoutingTable to retrieve the physical address for the specific IP address. If the RoutingTable does not know the address, it uses ARP to ask the network about a specific address. The lowest class is the EthernetInterface; this is the interface to the physical medium. The EthernetInterface is used both by IP and ARP.
The Packet class is the base of our design. It is used every time data is sent or received. A packet is built from three different classes, the Packet class, the DataChunk and the Header class.
The Packet class contains information about where the data in this packet is stored, and information necessary to reassemble fragmented packets. It also contains information about the headers needed to send or decode a packet. A Packet can contain one or more DataChunks, this allows for the possibility to support data located in different parts of the memory. It also avoids unnecessary data copying. Another advantage of this structure is that it makes the fragmentation and reassembly on the IP level fast and simple. The packet can contain zero or more headers. The headers are added as the packet travels through the protocol stack. E.g. a packet sent using the UDP protocol contains three headers (one for each protocol level) when it leaves the stack: the UDP header, the IP header and the ethernet header.
The DataChunk is the class containing information about where the data is located in memory, the length of the data, and a few other functions. The DataChunk, despite its name, does not contain any data. It uses pointers to locate the data in memory. We used this structure to avoid unnecessary copying of data.
The DataChunk contains simple functions, used to manipulate it. There are functions that add another DataChunk, or return the next. The function sumData is special, it is used by TCP and UDP when calculating the checksum on the DataChunks. The function returns the byte sum of the data the DataChunk points to.
The Header class contains the header information on the different protocol levels. Each Header class instance contains a pointer to the part of the memory where the header starts. It also contains functions to change and to extract information from the header.
The Header classes are derived from a common base class Header. This ensures that all Headers can later be put in the same list. There is one Header class for each header type, i.e. one TCPHeader, one UDPHeader and so on. The member functions implemented in the common Header class are functions handling the list of Headers, i.e. insert, remove, length and so on. The common methods of the different Header classes can be seen in figure 8.
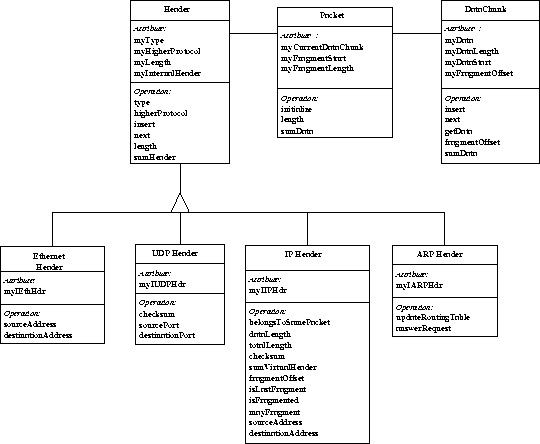
Figure 8: The Packet Hierarchy
The basic functions for the protocols are implemented in the Protocol class. All protocols inherit the basic functions from this class. The class hierarchy for the various protocols is based on the layers of the TCP/IP suite.
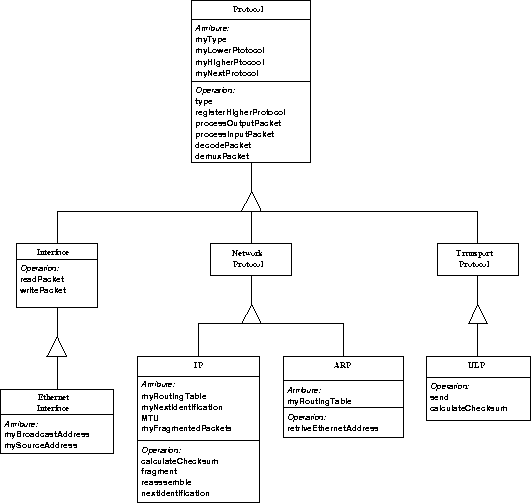
Figure 9: The Protocol Hierarchy
The next level in the class hierarchy adds more functionality to the protocol. The new functions added depend on which level the protocol is at. The network protocols IP and ARP inherit from NetworkProtocol, the transport protocols TCP, UDP and ICMP inherit from TransportProtocol. One of the achievements of using a common base class is a common interface between the different levels in the protocol stack. Another good aspect is that common parts of the code only have to be written once. The EthernetInterface is the interface to the physical network, in this case the ethernet card. Thanks to the common interface between the levels, we do not have to change everything if the physical network is changed. We only write a new class that inherits the basic functions from the Interface class and implement the interface specific functions.
In this section we describe the most important aspects and classes of our stack implementation. The protocols we actually implemented were only IP, UDP and ARP, and of course the interface to the ethernet.
The Packet class is a very important class, it contains all the information needed to send the data over the network. The packet contains Headers and DataChunks (see figure 10). The Headers are stored in a single linked list. The number of headers depends on where in the stack the packet is at the moment. The DataChunks are, just like the headers, stored in a single linked list. The Packet class contains methods which can manipulate the list of headers. It is possible to add, remove, and extract headers.
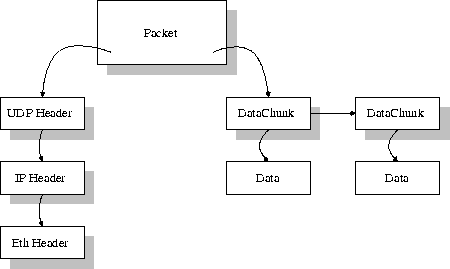
Figure 10: The Packet Structure
The implementation of the protocols is quite simple. Described below are the reassembly and fragmentation in IP, and the checksum calculation on the UDP level.
The reassembly starts when a fragmented packet arrives on the IP level. IP detects if the packet is fragmented, this is done with the method isFragmented in the IPHeader class. The method checks if the More Flag (MF) is set or if there is a fragment offset (see figure 2). The Packet fragment (referred to as Packet 1) is stored in a linked list. Here we used a list template from STL to make the implementation simple. Packet 1 consists of one Ethernet header, one IP header, and one DataChunk. The next step in the reassembly starts when the next packet fragment (referred to as Packet 2) arrives to the IP level. IP checks if the packet is fragmented in the same way as above. If the Packet is fragmented IP traverses the list with fragmented packets, and checks if the two fragments belong to the same Packet. The method belongsToSamePacket on the IPHeader returns the value TRUE if the last fragment belongs to the same Packet as the first fragment. The function checks if the identification field, and the source address is the same in the two IP headers. If the two fragments belongs to the same packet they need to be joined in some way. The way this is handled in our stack is especially easy. Basically we only have to add the DataChunk from Packet 2 to the DataChunk list in Packet 1, then delete Packet 2. This procedure continues as long as the fragmented packet is missing one or more fragments. When all fragments have arrived, Packet 1 is passed up to the next higher protocol level.
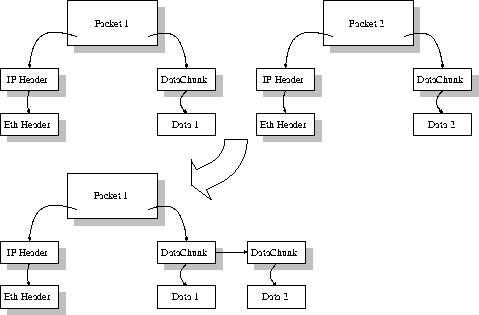
Figure 11: The Reassembly Procedure
The fragmentation occurs when a packet passed from the UDP level to the IP level is too large for the network below. This Packet is referred to as Packet 1. The data in Packet 1 has to be divided into two or more fragments to fit the network below. The first step in the fragmentation process is to check if it is allowed to fragment the packet. The method mayFragment in the IPHeader returns TRUE if the packet may be fragmented. The next step is to send Packet 1 with the first part of the data. Before passing the packet to the protocol level below, IP sets a few pointers in the DataChunk to point to the first part of the data. After this the packet is passed down to the next lower protocol level. IP then moves the pointers in the DataChunk so that they point to the second part of the data. Then it passes the packet to the protocol level below again. The same packet is used several times, only the pointers in the DataChunk are moved when sending the different fragments. This method was chosen because it is fast, but unfortunately not very simple to implement.
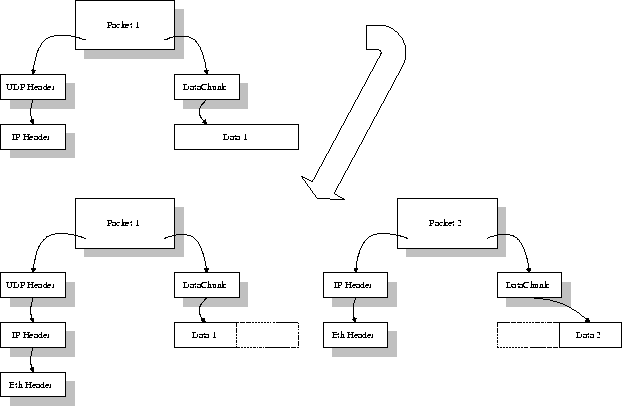
Figure 12: The Fragmentation Procedure
The checksum calculation in the TCP/IP suite is a simple checksum. The checksum is the one's complement sum of all 16-bit words.
The calculation of the checksum on the UDP level is a little complicated. The calculation is performed on the whole packet, the header, the data and a pseudo header, containing the source and destination address, the protocol, and the UDP length. It is the structure of the packet that makes the checksum calculation a bit complicated. The Packet may contain more than one DataChunk, which means that the data can be stored in different parts of the memory. When calculating the checksum we have to go through all DataChunks in a Packet and compute the sum of the data, and add them together. The method sumData in the DataChunk sums the data pointed out by one DataChunk. The IPHeader has a method called sumVirtualHeader, which sums the necessary parts of the IP header, needed to form the pseudo header. The third method is the method sumHeader in the Header class, it sums the bytes in the header, in this case the UDPHeader.
The checksum calculation starts when UDP calls calculateChecksum. The first action taken in the method is to calculate the sum of the UDP header. After that UDP has to find the IPHeader and call the method sumVirtualHeader to get the sum of the pseudo header. Finally the method sumData in the Packet is called. It traverses the DataChunk list and calls sumData for each DataChunk in the list.
The implementations of the functions calculating the checksum are in themselves not very complicated, but the combined result is not trivial. The functions should be comparably fast, but due to the double work done (touching all data once in the calculation of the checksum, and once in the copying of the packet) the total result is not as fast as we first had hoped.
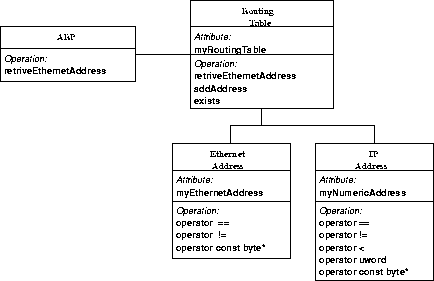
ARP is the protocol that finds the Ethernet address for a given IP address. When ARP finds an address it stores the address in the RoutingTable. The RoutingTable is a map (implemented as a binary search tree) containing address pairs. This map was taken from STL because all we wanted was an easy implementation, since ARP was not our main concern. The key into the map is an IP Address and the value is an Ethernet address. The RoutingTable has methods to add an address pair, to check if a pair exists, and to return an Ethernet address for a given IP address. If the address looked for does not exist in the RoutingTable, ARP has to send an ARPRequest on the network. ARP gets a reply, and adds that address to the RoutingTable.
The address classes have overloaded operators to make them easier to use. It is possible to check if an address is equal (or not equal) to another. In the case of IP also the < operator is overloaded. This made it possible to compare two IP addresses, and see which is greater. This was needed for the binary search tree to be sorted in the RoutingTable.
There are many parts of the TCP/IP suite which we did not implement in our stack, the main reason was the lack of time. Most of those parts are not important to run the stack and test the performance of the design.
We did not implement the option fields in the IP protocol. The reason was that the option field is of variable length, which causes some trouble when allocation the memory for the header. Another reason for not implementing the IP options was that most of the options are used for routing. Our stack is not meant to be run as a router, and therefore it does not support the routing options.
One major part that is not implemented is TCP itself. There are several reasons to why we did not implement TCP. One of them was the lack of time. Another one was that TCP is very complex, and a lot of people have already done much more work than we ever could do during the time we had. We thought it was better to concentrate on the UDP protocol and to evaluate its performance to make it as good as possible.
There are several ways to improve the performance of the stack. One of the largest bottlenecks to achieving high performance is the computation of checksums. The most simple way to eliminate the checksum overhead is to eliminate the checksums altogether. The elimination of the checksums produces a large reduction in processing time on large packets. There are in the current implementations options to disable the checksums, however the checksum computation exists for a good reason; sometimes a packet is corrupted during transmission.
The checksum computation in software is often redundant though. There already exists a CRC checksum on the Ethernet level. The messages sent directly over an Ethernet are therefore already protected against corruption. The CRC is a stronger algorithm for computing the checksum than those used for TCP/IP, and it is implemented in hardware. The cost of implementing the checksum in software is expensive, and often redundant. CRA is one way to increase performance by avoiding checksum computation in the case when it is redundant [12].
One must be careful though, about deciding when the TCP/UDP checksum is redundant. It is, however, reasonable to turn off the checksum when only crossing a single network which implements CRC in its hardware adapters.
Another bottleneck in our stack is the creation and destruction of objects. Whenever a packet arrives a Packet object is used, and Headers and DataChunks are created with the new operator. When a packet is sent on the Ethernet level the Headers, and DataChunks are destroyed with the delete operator. The creation and destruction of objects takes a lot of time. Since the Packet, Headers, and DataChunks are used every time a packet arrives from the network it is very important that the handling is fast. A way to decrease the time spent in new and delete is to use an object factory. An object factory is an object that stores and reuses old objects. Instead of calling new and delete, a function in the object factory is called and an object that has already been created is returned. To gain time the object factory creates the objects during the startup of the stack, when the use of time does not matter.